from napari_convpaint.conv_paint_model import ConvpaintModel
import numpy as np
import matplotlib.pyplot as plt
import skimage
c:\Users\roman\miniforge3\envs\cp-env02\Lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Using Convpaint programmatically (API)#
Loading a saved model and using it in a loop#
In one example workflow you might have interactively trained the model in the Napari GUI, and now want to use it programmatically in batch processing. Here we load a model trained on sample data and apply it to an image:
cpm = ConvpaintModel(model_path="../sample_data/lily_VGG16.pkl")
img = skimage.data.lily() # Load example image
img = np.moveaxis(img, -1, 0) # Move channel axis to first position, this is the convention throughout Convpaint
segmentation = cpm.segment(img)
For a simple illustration we extract the first 3 of the 4 channels of the image and display them as RGB. On the right, we show the predicted classes.
# Show the image and the annotations next to each other
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Plot the image
axes[0].imshow(skimage.data.lily()[:,:,:3], cmap='gray')
axes[0].set_title('Image')
cmap = plt.get_cmap('tab20', 3)
cmap.set_under('white')
# Plot the prediction
axes[1].imshow(segmentation, cmap=cmap,interpolation='nearest')#,vmin=1,vmax=3)
axes[1].set_title('Prediction')
#disable x and y ticks
for ax in axes:
ax.set_xticks([])
ax.set_yticks([])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [0..4095].
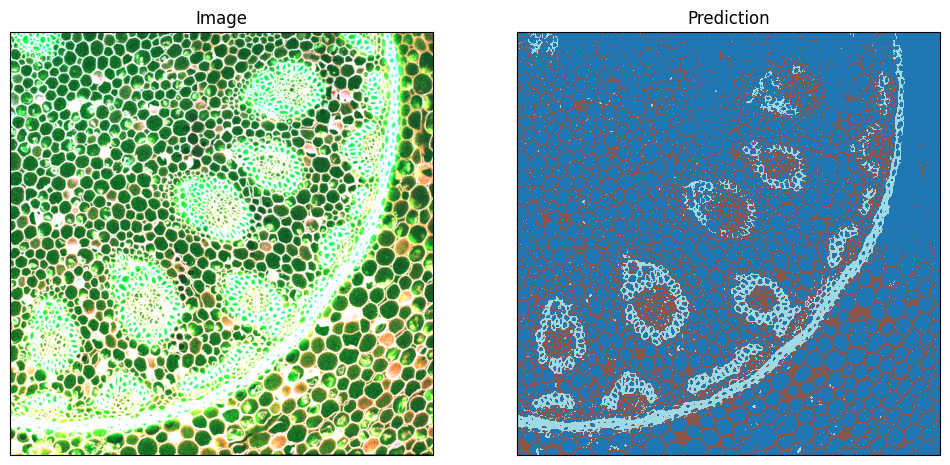
Creating and training a new model using the API#
We can also create new models from scratch programatically. Like this, we can easily compare the performance of different models.
First let’s look at all the available feature extractors:
ConvpaintModel.get_fe_models_types()
{'vgg16': napari_convpaint.conv_paint_nnlayers.Hookmodel,
'efficient_netb0': napari_convpaint.conv_paint_nnlayers.Hookmodel,
'convnext': napari_convpaint.conv_paint_nnlayers.Hookmodel,
'gaussian_features': napari_convpaint.conv_paint_gaussian.GaussianFeatures,
'dinov2_vits14_reg': napari_convpaint.conv_paint_dino.DinoFeatures,
'combo_dino_vgg': napari_convpaint.conv_paint_combo_fe.ComboFeatures,
'combo_dino_gauss': napari_convpaint.conv_paint_combo_fe.ComboFeatures,
'combo_dino_ilastik': napari_convpaint.conv_paint_combo_fe.ComboFeatures,
'vit_small_patch14_reg4_dinov2': napari_convpaint.conv_paint_dino_jafar.DinoJafarFeatures,
'cellpose_backbone': napari_convpaint.conv_paint_cellpose.CellposeFeatures,
'ilastik_2d': napari_convpaint.conv_paint_ilastik.IlastikFeatures}
When using CNN such as VGG16 as feature extractor, we need to supply the layers we want to use.
We can print out the selectable layers like this:
cpm2 = ConvpaintModel()
cpm2.get_fe_layer_keys()
['features.0 Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.2 Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.5 Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.7 Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.10 Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.12 Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.14 Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.17 Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.19 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.21 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.24 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.26 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))',
'features.28 Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))']
By default, we’ve created a model using VGG16 with just the first layer for feature extraction:
cpm2.get_param("fe_layers")
['features.0 Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))']
Lets create a new VGG16 model using the first 2 layers. We store all the necessary settings in the ConvpaintModel object, which is usually created from the GUI toggles. Note that the layers can either be specified by names or as indices (among the available layers).
cpm3 = ConvpaintModel(fe_name="vgg16", fe_layers=[0, 1])
cpm3.get_param("fe_layers")
[0, 1]
Besides the layers for CNNs, there are several other options that can be set in the ConvpaintModel object:
fe_scalingsspecifies the levels of downscaling to use for feature extraction (1 is the original size)fe_orderspecifies the spline order used to upscale small feature maps (either from the downscaling, or from aggregation in the neural network).with
fe_use_min_features=True, only the n-first features of each output layer are selected, n being the number of features of the layer which outputs the least of them. This can help balance the weight of different layers.normalizewill normalize the image so that it matches more closely the input expected by the pre-trained network.image_downsampleallows to use a smaller version of the image as input. Note that this doesn’t change the size of the predicted output, as it gets rescaled to the original size in the end.
For a comprehensive description of all parameters and options, please refer to the separate page.
Let’s create a custom model. As you see below, except for the fe_name and layers (and gpu), all parameters can easily be adjusted after initialization - either one at a time, or multiples in one call:
cpm4 = ConvpaintModel(fe_name="vgg16", fe_layers=[0, 1])
cpm4.set_param("fe_scalings", [1, 2])
cpm4.set_params(fe_order=0, fe_use_min_features=False, image_downsample=3)
Train and test the model on artificial data:
# create a noisy image
img = np.random.rand(200,200)
factor = 0.3
img[:50,:] = img[:50,:]*factor
img[80:100,:] = img[80:100,:]*factor
# draw small rectangle as annotations
annotations = np.zeros((200,200))
annotations[10:30,10:30] = 1 #class 1
annotations[170:190,170:190] = 2 #class 2
# train the classifier to predict the annotations from the features
cpm4.train(img, annotations)
# predict the annotations from the image
segmentation = cpm4.segment(img)
C:\Users\roman\Documents\Convpaint\hinderling-cp\napari-convpaint\src\napari_convpaint\conv_paint_model.py:1506: UserWarning: Annotations for image 0 are not of type int32. Converting to int32.
warnings.warn(f'Annotations for image {i} are not of type int32. Converting to int32.')
0: learn: 0.5503165 total: 145ms remaining: 14.4s
1: learn: 0.4330621 total: 147ms remaining: 7.22s
2: learn: 0.3625376 total: 150ms remaining: 4.85s
3: learn: 0.2958804 total: 153ms remaining: 3.67s
4: learn: 0.2345301 total: 155ms remaining: 2.95s
5: learn: 0.1966157 total: 158ms remaining: 2.47s
6: learn: 0.1628511 total: 160ms remaining: 2.12s
7: learn: 0.1422693 total: 162ms remaining: 1.86s
8: learn: 0.1223218 total: 164ms remaining: 1.65s
9: learn: 0.1072466 total: 166ms remaining: 1.49s
10: learn: 0.0950612 total: 168ms remaining: 1.36s
11: learn: 0.0840313 total: 170ms remaining: 1.24s
12: learn: 0.0748385 total: 172ms remaining: 1.15s
13: learn: 0.0678239 total: 174ms remaining: 1.07s
14: learn: 0.0612400 total: 176ms remaining: 997ms
15: learn: 0.0541271 total: 178ms remaining: 934ms
16: learn: 0.0505085 total: 180ms remaining: 878ms
17: learn: 0.0462722 total: 182ms remaining: 828ms
18: learn: 0.0438944 total: 184ms remaining: 783ms
19: learn: 0.0391880 total: 186ms remaining: 743ms
20: learn: 0.0368704 total: 188ms remaining: 706ms
21: learn: 0.0339036 total: 190ms remaining: 674ms
22: learn: 0.0319389 total: 192ms remaining: 644ms
23: learn: 0.0299572 total: 194ms remaining: 615ms
24: learn: 0.0275961 total: 196ms remaining: 589ms
25: learn: 0.0265592 total: 198ms remaining: 565ms
26: learn: 0.0252884 total: 200ms remaining: 542ms
27: learn: 0.0237065 total: 202ms remaining: 520ms
28: learn: 0.0224039 total: 205ms remaining: 502ms
29: learn: 0.0212422 total: 207ms remaining: 484ms
30: learn: 0.0201063 total: 209ms remaining: 466ms
31: learn: 0.0194672 total: 211ms remaining: 449ms
32: learn: 0.0187031 total: 213ms remaining: 433ms
33: learn: 0.0178967 total: 215ms remaining: 417ms
34: learn: 0.0169173 total: 217ms remaining: 403ms
35: learn: 0.0160058 total: 219ms remaining: 389ms
36: learn: 0.0152015 total: 221ms remaining: 376ms
37: learn: 0.0145148 total: 223ms remaining: 364ms
38: learn: 0.0139900 total: 225ms remaining: 352ms
39: learn: 0.0134231 total: 227ms remaining: 340ms
40: learn: 0.0129785 total: 229ms remaining: 329ms
41: learn: 0.0125471 total: 231ms remaining: 319ms
42: learn: 0.0120575 total: 233ms remaining: 308ms
43: learn: 0.0116022 total: 234ms remaining: 298ms
44: learn: 0.0113342 total: 236ms remaining: 289ms
45: learn: 0.0110280 total: 238ms remaining: 280ms
46: learn: 0.0107504 total: 241ms remaining: 271ms
47: learn: 0.0103991 total: 243ms remaining: 263ms
48: learn: 0.0101068 total: 245ms remaining: 255ms
49: learn: 0.0097844 total: 246ms remaining: 246ms
50: learn: 0.0095382 total: 248ms remaining: 239ms
51: learn: 0.0093908 total: 250ms remaining: 231ms
52: learn: 0.0092236 total: 252ms remaining: 224ms
53: learn: 0.0089554 total: 254ms remaining: 217ms
54: learn: 0.0088031 total: 256ms remaining: 210ms
55: learn: 0.0086493 total: 258ms remaining: 203ms
56: learn: 0.0084800 total: 260ms remaining: 196ms
57: learn: 0.0082808 total: 262ms remaining: 190ms
58: learn: 0.0081644 total: 264ms remaining: 184ms
59: learn: 0.0080434 total: 266ms remaining: 178ms
60: learn: 0.0078585 total: 268ms remaining: 172ms
61: learn: 0.0075358 total: 270ms remaining: 166ms
62: learn: 0.0074239 total: 273ms remaining: 160ms
63: learn: 0.0073114 total: 275ms remaining: 155ms
64: learn: 0.0071696 total: 277ms remaining: 149ms
65: learn: 0.0070035 total: 279ms remaining: 144ms
66: learn: 0.0069156 total: 281ms remaining: 138ms
67: learn: 0.0068254 total: 283ms remaining: 133ms
68: learn: 0.0066572 total: 285ms remaining: 128ms
69: learn: 0.0065722 total: 287ms remaining: 123ms
70: learn: 0.0064895 total: 289ms remaining: 118ms
71: learn: 0.0063920 total: 292ms remaining: 113ms
72: learn: 0.0062870 total: 294ms remaining: 109ms
73: learn: 0.0061250 total: 295ms remaining: 104ms
74: learn: 0.0060021 total: 297ms remaining: 99.1ms
75: learn: 0.0058918 total: 299ms remaining: 94.6ms
76: learn: 0.0058215 total: 301ms remaining: 90.1ms
77: learn: 0.0056995 total: 304ms remaining: 85.7ms
78: learn: 0.0056376 total: 306ms remaining: 81.4ms
79: learn: 0.0055287 total: 308ms remaining: 77ms
80: learn: 0.0054683 total: 310ms remaining: 72.7ms
81: learn: 0.0053668 total: 312ms remaining: 68.5ms
82: learn: 0.0052915 total: 314ms remaining: 64.3ms
83: learn: 0.0051776 total: 316ms remaining: 60.2ms
84: learn: 0.0051290 total: 318ms remaining: 56.1ms
85: learn: 0.0050417 total: 319ms remaining: 52ms
86: learn: 0.0049660 total: 322ms remaining: 48ms
87: learn: 0.0049046 total: 324ms remaining: 44.1ms
88: learn: 0.0048686 total: 326ms remaining: 40.2ms
89: learn: 0.0047724 total: 327ms remaining: 36.4ms
90: learn: 0.0047078 total: 329ms remaining: 32.6ms
91: learn: 0.0046449 total: 331ms remaining: 28.8ms
92: learn: 0.0045718 total: 333ms remaining: 25ms
93: learn: 0.0045107 total: 334ms remaining: 21.3ms
94: learn: 0.0044516 total: 337ms remaining: 17.7ms
95: learn: 0.0043861 total: 338ms remaining: 14.1ms
96: learn: 0.0043576 total: 340ms remaining: 10.5ms
97: learn: 0.0042957 total: 342ms remaining: 6.98ms
98: learn: 0.0042351 total: 344ms remaining: 3.47ms
99: learn: 0.0041767 total: 345ms remaining: 0us
# show the image and the annotations
fig, axes = plt.subplots(1, 3, figsize=(12, 6))
# Plot the image
axes[0].imshow(img, cmap='gray')
axes[0].set_title('Image')
cmap = plt.get_cmap('tab20')
cmap.set_under('white')
# Plot the annotations
axes[1].imshow(annotations, cmap=cmap,interpolation='nearest',vmin=1,vmax=3)
axes[1].set_title('Annotations')
# Plot the prediction
axes[2].imshow(segmentation, cmap=cmap,interpolation='nearest',vmin=1,vmax=3)
axes[2].set_title('Prediction')
#disable x and y ticks
for ax in axes:
ax.set_xticks([])
ax.set_yticks([])
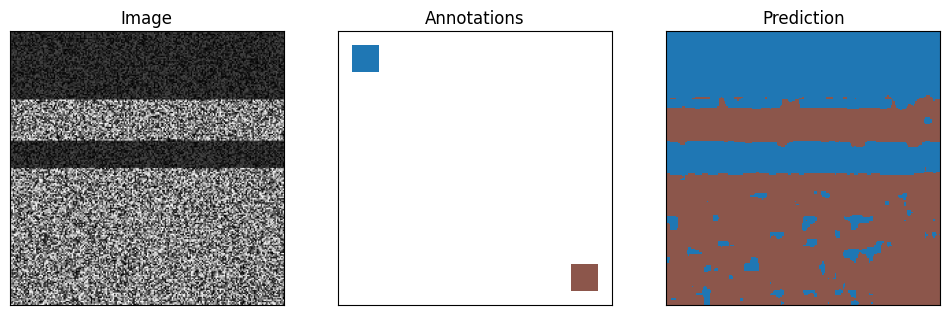
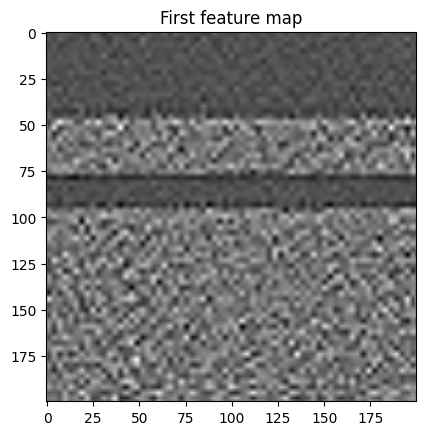
The selected output layers have 64 and 64 output features and we’re using three scalings, so in total we have (64+64)*3 = 384 features. With our ConvpaintModel, we can also extract those features to display and analyze them further:
features = cpm4.get_feature_image(img)
print(f"Number of features: {features.shape}")
plt.imshow(features[0], cmap='gray')
plt.title('First feature map')
plt.show()
Number of features: (256, 200, 200)
Running Convpaint in a loop for batch processing#
num_images = 10 # Number of images to generate
imgs = []
segmentations = []
for i in range(num_images):
# Create a noisy image
img = np.random.rand(200, 200)
start_row = np.random.randint(0, 150)
end_row = start_row + np.random.randint(20, 50)
img[start_row:end_row, :] = img[start_row:end_row, :] * 0.5
# Make prediction
segmentation = cpm4.segment(img)
imgs.append(img)
segmentations.append(segmentation)
# Create a figure with a grid of subplots
fig, axs = plt.subplots(2, num_images, figsize=(12, 3))
for i in range(num_images):
# Plot sample image
axs[0, i].imshow(imgs[i], cmap='gray')
axs[0, i].set_title(f'{i+1}')
axs[0, i].set_xticks([])
axs[0, i].set_yticks([])
# Plot prediction
axs[1, i].imshow(segmentations[i], cmap=cmap, interpolation='nearest', vmin=1, vmax=3)
axs[1, i].set_title(f'')
axs[1, i].set_xticks([])
axs[1, i].set_yticks([])
# Add y labels
axs[0, 0].set_ylabel('Image')
axs[1, 0].set_ylabel('Prediction')
plt.tight_layout()
plt.show()
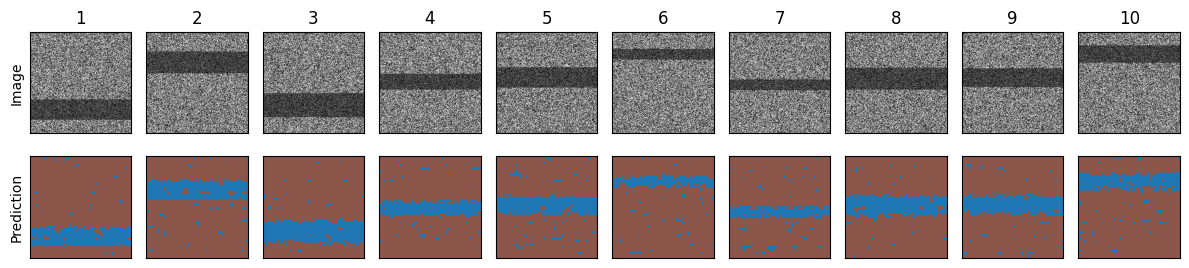
Creating a model using DINOv2 as feature extractor#
For the ViT based DINOv2 model we’re not selecting the layers, and instead just extract all patch based features.
Note that here, we are using another option to initialize a ConvpaintModel. Using an alias to create a pre-defined model is in fact the simplest way to get started with Convpaint. For details, refer to the Feature Extractor page.
Importantly, here we are handling images with an additional dimension. Hence, we need to tell the model what that dimension represents: a third “spatial” dimension (in particular z or time), or a “channel” dimension (for example, RGB color channels). Here, we set multi_channel_img to True in accordance with the RGB color channels of the image.
cpm_dino = ConvpaintModel(alias="dino")
cpm_dino.set_param("multi_channel_img", True)
# create new dataset
img = skimage.data.stereo_motorcycle()
train_img = np.moveaxis(img[0], -1, 0)
pred_img = np.moveaxis(img[1], -1, 0)
annotations = np.zeros(img[0][:,:,0].shape)
#foreground [y,x]
annotations[50:100,50:100] = 1
annotations[450:500,500:550] = 1
#background [x,y]
annotations[200:250,400:450] = 2
annotations[300:350,200:400] = 2
# Train the model
cpm_dino.train(train_img, annotations)
# Use it to segment the image
segmentation = cpm_dino.segment(image=pred_img)
C:\Users\roman/.cache\torch\hub\facebookresearch_dinov2_main\dinov2\layers\swiglu_ffn.py:51: UserWarning: xFormers is not available (SwiGLU)
warnings.warn("xFormers is not available (SwiGLU)")
C:\Users\roman/.cache\torch\hub\facebookresearch_dinov2_main\dinov2\layers\attention.py:33: UserWarning: xFormers is not available (Attention)
warnings.warn("xFormers is not available (Attention)")
C:\Users\roman/.cache\torch\hub\facebookresearch_dinov2_main\dinov2\layers\block.py:40: UserWarning: xFormers is not available (Block)
warnings.warn("xFormers is not available (Block)")
C:\Users\roman\Documents\Convpaint\hinderling-cp\napari-convpaint\src\napari_convpaint\conv_paint_model.py:1506: UserWarning: Annotations for image 0 are not of type int32. Converting to int32.
warnings.warn(f'Annotations for image {i} are not of type int32. Converting to int32.')
0: learn: 0.3768599 total: 23.4ms remaining: 2.31s
1: learn: 0.2002017 total: 32.7ms remaining: 1.6s
2: learn: 0.1085167 total: 43.8ms remaining: 1.42s
3: learn: 0.0631080 total: 53.6ms remaining: 1.29s
4: learn: 0.0358521 total: 63.7ms remaining: 1.21s
5: learn: 0.0219060 total: 73ms remaining: 1.14s
6: learn: 0.0140858 total: 82.7ms remaining: 1.1s
7: learn: 0.0092302 total: 92.3ms remaining: 1.06s
8: learn: 0.0062938 total: 101ms remaining: 1.03s
9: learn: 0.0045885 total: 111ms remaining: 1s
10: learn: 0.0032304 total: 120ms remaining: 973ms
11: learn: 0.0024106 total: 130ms remaining: 954ms
12: learn: 0.0018580 total: 139ms remaining: 933ms
13: learn: 0.0014287 total: 149ms remaining: 913ms
14: learn: 0.0011273 total: 158ms remaining: 895ms
15: learn: 0.0009283 total: 167ms remaining: 877ms
16: learn: 0.0007666 total: 176ms remaining: 859ms
17: learn: 0.0006563 total: 184ms remaining: 840ms
18: learn: 0.0005687 total: 194ms remaining: 826ms
19: learn: 0.0004960 total: 202ms remaining: 809ms
20: learn: 0.0004467 total: 212ms remaining: 797ms
21: learn: 0.0004095 total: 220ms remaining: 780ms
22: learn: 0.0003607 total: 230ms remaining: 770ms
23: learn: 0.0003323 total: 239ms remaining: 755ms
24: learn: 0.0003091 total: 248ms remaining: 743ms
25: learn: 0.0002905 total: 256ms remaining: 730ms
26: learn: 0.0002741 total: 265ms remaining: 716ms
27: learn: 0.0002594 total: 273ms remaining: 703ms
28: learn: 0.0002490 total: 282ms remaining: 690ms
29: learn: 0.0002490 total: 290ms remaining: 677ms
30: learn: 0.0002490 total: 299ms remaining: 665ms
31: learn: 0.0002490 total: 307ms remaining: 653ms
32: learn: 0.0002227 total: 316ms remaining: 642ms
33: learn: 0.0002151 total: 325ms remaining: 631ms
34: learn: 0.0001998 total: 334ms remaining: 620ms
35: learn: 0.0001998 total: 342ms remaining: 608ms
36: learn: 0.0001998 total: 350ms remaining: 596ms
37: learn: 0.0001998 total: 360ms remaining: 587ms
38: learn: 0.0001997 total: 369ms remaining: 578ms
39: learn: 0.0001998 total: 379ms remaining: 568ms
40: learn: 0.0001998 total: 388ms remaining: 558ms
41: learn: 0.0001969 total: 396ms remaining: 547ms
42: learn: 0.0001933 total: 405ms remaining: 537ms
43: learn: 0.0001933 total: 413ms remaining: 526ms
44: learn: 0.0001932 total: 422ms remaining: 516ms
45: learn: 0.0001895 total: 430ms remaining: 505ms
46: learn: 0.0001894 total: 439ms remaining: 495ms
47: learn: 0.0001862 total: 448ms remaining: 485ms
48: learn: 0.0001861 total: 457ms remaining: 476ms
49: learn: 0.0001861 total: 466ms remaining: 466ms
50: learn: 0.0001861 total: 475ms remaining: 456ms
51: learn: 0.0001860 total: 483ms remaining: 446ms
52: learn: 0.0001860 total: 492ms remaining: 436ms
53: learn: 0.0001860 total: 501ms remaining: 426ms
54: learn: 0.0001860 total: 510ms remaining: 417ms
55: learn: 0.0001860 total: 518ms remaining: 407ms
56: learn: 0.0001859 total: 528ms remaining: 398ms
57: learn: 0.0001859 total: 536ms remaining: 388ms
58: learn: 0.0001860 total: 545ms remaining: 379ms
59: learn: 0.0001859 total: 554ms remaining: 370ms
60: learn: 0.0001859 total: 563ms remaining: 360ms
61: learn: 0.0001825 total: 572ms remaining: 351ms
62: learn: 0.0001791 total: 581ms remaining: 341ms
63: learn: 0.0001791 total: 590ms remaining: 332ms
64: learn: 0.0001763 total: 598ms remaining: 322ms
65: learn: 0.0001763 total: 607ms remaining: 313ms
66: learn: 0.0001730 total: 616ms remaining: 303ms
67: learn: 0.0001730 total: 625ms remaining: 294ms
68: learn: 0.0001730 total: 633ms remaining: 285ms
69: learn: 0.0001730 total: 642ms remaining: 275ms
70: learn: 0.0001729 total: 651ms remaining: 266ms
71: learn: 0.0001729 total: 660ms remaining: 256ms
72: learn: 0.0001679 total: 669ms remaining: 247ms
73: learn: 0.0001679 total: 677ms remaining: 238ms
74: learn: 0.0001680 total: 687ms remaining: 229ms
75: learn: 0.0001680 total: 695ms remaining: 220ms
76: learn: 0.0001680 total: 704ms remaining: 210ms
77: learn: 0.0001680 total: 713ms remaining: 201ms
78: learn: 0.0001680 total: 722ms remaining: 192ms
79: learn: 0.0001680 total: 730ms remaining: 183ms
80: learn: 0.0001679 total: 739ms remaining: 173ms
81: learn: 0.0001680 total: 747ms remaining: 164ms
82: learn: 0.0001620 total: 756ms remaining: 155ms
83: learn: 0.0001620 total: 764ms remaining: 146ms
84: learn: 0.0001620 total: 773ms remaining: 136ms
85: learn: 0.0001620 total: 782ms remaining: 127ms
86: learn: 0.0001619 total: 791ms remaining: 118ms
87: learn: 0.0001619 total: 800ms remaining: 109ms
88: learn: 0.0001619 total: 809ms remaining: 100ms
89: learn: 0.0001619 total: 818ms remaining: 90.8ms
90: learn: 0.0001620 total: 826ms remaining: 81.7ms
91: learn: 0.0001619 total: 836ms remaining: 72.7ms
92: learn: 0.0001620 total: 844ms remaining: 63.5ms
93: learn: 0.0001620 total: 853ms remaining: 54.5ms
94: learn: 0.0001619 total: 862ms remaining: 45.3ms
95: learn: 0.0001620 total: 871ms remaining: 36.3ms
96: learn: 0.0001620 total: 880ms remaining: 27.2ms
97: learn: 0.0001619 total: 889ms remaining: 18.1ms
98: learn: 0.0001619 total: 898ms remaining: 9.07ms
99: learn: 0.0001619 total: 906ms remaining: 0us
# show the image and the annotations
fig, axes = plt.subplots(1, 4, figsize=(12, 8))
# Plot the image
axes[0].imshow(img[0], cmap='gray')
axes[0].set_title(f'Stereo image 0 (training)')
cmap = plt.get_cmap('tab20')
cmap.set_under('white')
# Plot the annotations
axes[1].imshow(annotations, cmap=cmap, interpolation='nearest', vmin=1, vmax=3)
axes[1].set_title('Annotations')
# Plot the image to predict
axes[2].imshow(img[1], cmap='gray')
axes[2].set_title(f'Stereo image 1 (to predict)')
# Plot the prediction
axes[3].imshow(segmentation, cmap=cmap, interpolation='nearest', vmin=1, vmax=3)
axes[3].set_title('Prediction')
#disable x and y ticks
for ax in axes:
ax.set_xticks([])
ax.set_yticks([])

Visualizing the extracted DINOv2 features#
feature_image = cpm_dino.get_feature_image(train_img)
num_features = feature_image.shape[0]
print(f"Extracted {num_features} features.")
grid_size = 5
random_features = np.random.choice(num_features, grid_size*grid_size)
fig, axes = plt.subplots(grid_size, grid_size, figsize=(12, 8))
for i, ax in enumerate(axes.flat):
ax.imshow(feature_image[random_features[i]], cmap='viridis')
ax.set_xticks([])
ax.set_yticks([])
# Set w/h distance between subplots to 0
plt.subplots_adjust(wspace=0.1, hspace=0.1)
Extracted 384 features.

Combining features from multiple models#
The strengths of different feature extractors can be combined by concatenating their outputs. For example, the good spatial resolution of VGG16 can be combined with the rich semantic features of DINOv2. This leads to very successful segmentations on some datasets.
We are providing a selection of pre-defined combo feature extractors. You can use these out of the box or as a starting point for your own custom configurations.
cpm_combo = ConvpaintModel(fe_name="combo_dino_vgg", multi_channel_img=True)
train_img = np.moveaxis(skimage.data.stereo_motorcycle()[0],-1,0)
pred_img = np.moveaxis(skimage.data.stereo_motorcycle()[1],-1,0)
# Train on the first image
cpm_combo.train(train_img, annotations)
# Predict on the second
segmentation = cpm_combo.segment(pred_img)
C:\Users\roman\Documents\Convpaint\hinderling-cp\napari-convpaint\src\napari_convpaint\conv_paint_model.py:1506: UserWarning: Annotations for image 0 are not of type int32. Converting to int32.
warnings.warn(f'Annotations for image {i} are not of type int32. Converting to int32.')
0: learn: 0.3776665 total: 16.6ms remaining: 1.64s
1: learn: 0.2040959 total: 30.7ms remaining: 1.5s
2: learn: 0.1167316 total: 44.4ms remaining: 1.44s
3: learn: 0.0662353 total: 57.5ms remaining: 1.38s
4: learn: 0.0377773 total: 70.2ms remaining: 1.33s
5: learn: 0.0241646 total: 83.7ms remaining: 1.31s
6: learn: 0.0152460 total: 97.1ms remaining: 1.29s
7: learn: 0.0103850 total: 110ms remaining: 1.27s
8: learn: 0.0070520 total: 124ms remaining: 1.25s
9: learn: 0.0048217 total: 136ms remaining: 1.23s
10: learn: 0.0034012 total: 149ms remaining: 1.2s
11: learn: 0.0025735 total: 162ms remaining: 1.19s
12: learn: 0.0019695 total: 174ms remaining: 1.17s
13: learn: 0.0015157 total: 188ms remaining: 1.16s
14: learn: 0.0012130 total: 201ms remaining: 1.14s
15: learn: 0.0009815 total: 214ms remaining: 1.12s
16: learn: 0.0007977 total: 228ms remaining: 1.11s
17: learn: 0.0006455 total: 241ms remaining: 1.1s
18: learn: 0.0005496 total: 254ms remaining: 1.08s
19: learn: 0.0004818 total: 267ms remaining: 1.07s
20: learn: 0.0004188 total: 280ms remaining: 1.05s
21: learn: 0.0003605 total: 292ms remaining: 1.03s
22: learn: 0.0003103 total: 304ms remaining: 1.02s
23: learn: 0.0002718 total: 317ms remaining: 1s
24: learn: 0.0002468 total: 330ms remaining: 990ms
25: learn: 0.0002377 total: 342ms remaining: 973ms
26: learn: 0.0002377 total: 354ms remaining: 956ms
27: learn: 0.0002185 total: 365ms remaining: 939ms
28: learn: 0.0002025 total: 378ms remaining: 926ms
29: learn: 0.0001869 total: 391ms remaining: 912ms
30: learn: 0.0001869 total: 402ms remaining: 895ms
31: learn: 0.0001831 total: 414ms remaining: 879ms
32: learn: 0.0001797 total: 426ms remaining: 865ms
33: learn: 0.0001797 total: 437ms remaining: 849ms
34: learn: 0.0001797 total: 448ms remaining: 832ms
35: learn: 0.0001797 total: 460ms remaining: 818ms
36: learn: 0.0001797 total: 472ms remaining: 803ms
37: learn: 0.0001796 total: 483ms remaining: 788ms
38: learn: 0.0001768 total: 495ms remaining: 774ms
39: learn: 0.0001735 total: 507ms remaining: 760ms
40: learn: 0.0001735 total: 518ms remaining: 745ms
41: learn: 0.0001735 total: 529ms remaining: 731ms
42: learn: 0.0001735 total: 541ms remaining: 717ms
43: learn: 0.0001708 total: 552ms remaining: 703ms
44: learn: 0.0001676 total: 564ms remaining: 689ms
45: learn: 0.0001676 total: 576ms remaining: 676ms
46: learn: 0.0001676 total: 588ms remaining: 663ms
47: learn: 0.0001676 total: 601ms remaining: 651ms
48: learn: 0.0001676 total: 613ms remaining: 638ms
49: learn: 0.0001676 total: 625ms remaining: 625ms
50: learn: 0.0001583 total: 637ms remaining: 612ms
51: learn: 0.0001531 total: 648ms remaining: 598ms
52: learn: 0.0001531 total: 659ms remaining: 585ms
53: learn: 0.0001531 total: 671ms remaining: 572ms
54: learn: 0.0001531 total: 683ms remaining: 559ms
55: learn: 0.0001531 total: 694ms remaining: 545ms
56: learn: 0.0001485 total: 706ms remaining: 533ms
57: learn: 0.0001438 total: 718ms remaining: 520ms
58: learn: 0.0001438 total: 729ms remaining: 507ms
59: learn: 0.0001438 total: 741ms remaining: 494ms
60: learn: 0.0001438 total: 753ms remaining: 482ms
61: learn: 0.0001438 total: 765ms remaining: 469ms
62: learn: 0.0001438 total: 777ms remaining: 456ms
63: learn: 0.0001438 total: 789ms remaining: 444ms
64: learn: 0.0001438 total: 800ms remaining: 431ms
65: learn: 0.0001438 total: 812ms remaining: 418ms
66: learn: 0.0001438 total: 823ms remaining: 405ms
67: learn: 0.0001438 total: 835ms remaining: 393ms
68: learn: 0.0001438 total: 847ms remaining: 381ms
69: learn: 0.0001438 total: 859ms remaining: 368ms
70: learn: 0.0001438 total: 872ms remaining: 356ms
71: learn: 0.0001438 total: 884ms remaining: 344ms
72: learn: 0.0001392 total: 895ms remaining: 331ms
73: learn: 0.0001392 total: 907ms remaining: 319ms
74: learn: 0.0001392 total: 920ms remaining: 307ms
75: learn: 0.0001392 total: 931ms remaining: 294ms
76: learn: 0.0001392 total: 942ms remaining: 282ms
77: learn: 0.0001392 total: 955ms remaining: 269ms
78: learn: 0.0001392 total: 968ms remaining: 257ms
79: learn: 0.0001392 total: 981ms remaining: 245ms
80: learn: 0.0001392 total: 992ms remaining: 233ms
81: learn: 0.0001392 total: 1.01s remaining: 221ms
82: learn: 0.0001349 total: 1.02s remaining: 209ms
83: learn: 0.0001349 total: 1.03s remaining: 197ms
84: learn: 0.0001349 total: 1.05s remaining: 185ms
85: learn: 0.0001348 total: 1.06s remaining: 173ms
86: learn: 0.0001348 total: 1.08s remaining: 161ms
87: learn: 0.0001348 total: 1.09s remaining: 149ms
88: learn: 0.0001348 total: 1.1s remaining: 136ms
89: learn: 0.0001348 total: 1.12s remaining: 124ms
90: learn: 0.0001348 total: 1.13s remaining: 112ms
91: learn: 0.0001348 total: 1.15s remaining: 99.7ms
92: learn: 0.0001348 total: 1.16s remaining: 87.3ms
93: learn: 0.0001348 total: 1.17s remaining: 74.9ms
94: learn: 0.0001348 total: 1.18s remaining: 62.4ms
95: learn: 0.0001348 total: 1.2s remaining: 50ms
96: learn: 0.0001348 total: 1.22s remaining: 37.8ms
97: learn: 0.0001348 total: 1.24s remaining: 25.3ms
98: learn: 0.0001348 total: 1.25s remaining: 12.6ms
99: learn: 0.0001348 total: 1.27s remaining: 0us
# show the image and the annotations
fig, axes = plt.subplots(1, 4, figsize=(12, 6))
# Plot the image
axes[0].imshow(img[0], cmap='gray')
cmap = plt.get_cmap('tab20')
cmap.set_under('white')
# Plot the annotations
axes[1].imshow(annotations, cmap=cmap, interpolation='nearest', vmin=1, vmax=3)
# Plot the image to predict
axes[2].imshow(img[1], cmap='gray')
# Plot the prediction
axes[3].imshow(segmentation, cmap=cmap, interpolation='nearest', vmin=1, vmax=3)
# Disable x and y ticks
for ax in axes:
ax.set_xticks([])
ax.set_yticks([])

Visual comparison of features extracted by DINOv2 vs. VGG16#
cpm_vgg = ConvpaintModel(fe_name="vgg16", multi_channel_img=True)
features_vgg = cpm_vgg.get_feature_image(train_img)
cpm_dino = ConvpaintModel(fe_name="dinov2_vits14_reg", multi_channel_img=True)
features_dino = cpm_dino.get_feature_image(train_img)
fig, axes = plt.subplots(1, 3, figsize=(12, 12))
# Plot img, and a random feature each from dinov2 and vgg16
axes[1].imshow(features_dino[22,:,:], cmap='viridis')
axes[1].set_title('DINOV2 feature')
axes[2].imshow(features_vgg[22,:,:], cmap='viridis')
axes[2].set_title('VGG16 feature')
axes[0].imshow(img[0])
axes[0].set_title('Original Image')
for ax in axes:
ax.set_xticks([])
ax.set_yticks([])
plt.subplots_adjust(wspace=0.1, hspace=0.1)
