Description#
Classifiers, such as Random Forest or Catboost are very powerful machine learning tools for image segmentation. The most famous example is the very popular open source software Ilastik. There are also popular plugins to perform these tasks right in napari, such as napari-apoc by Robert Haase.
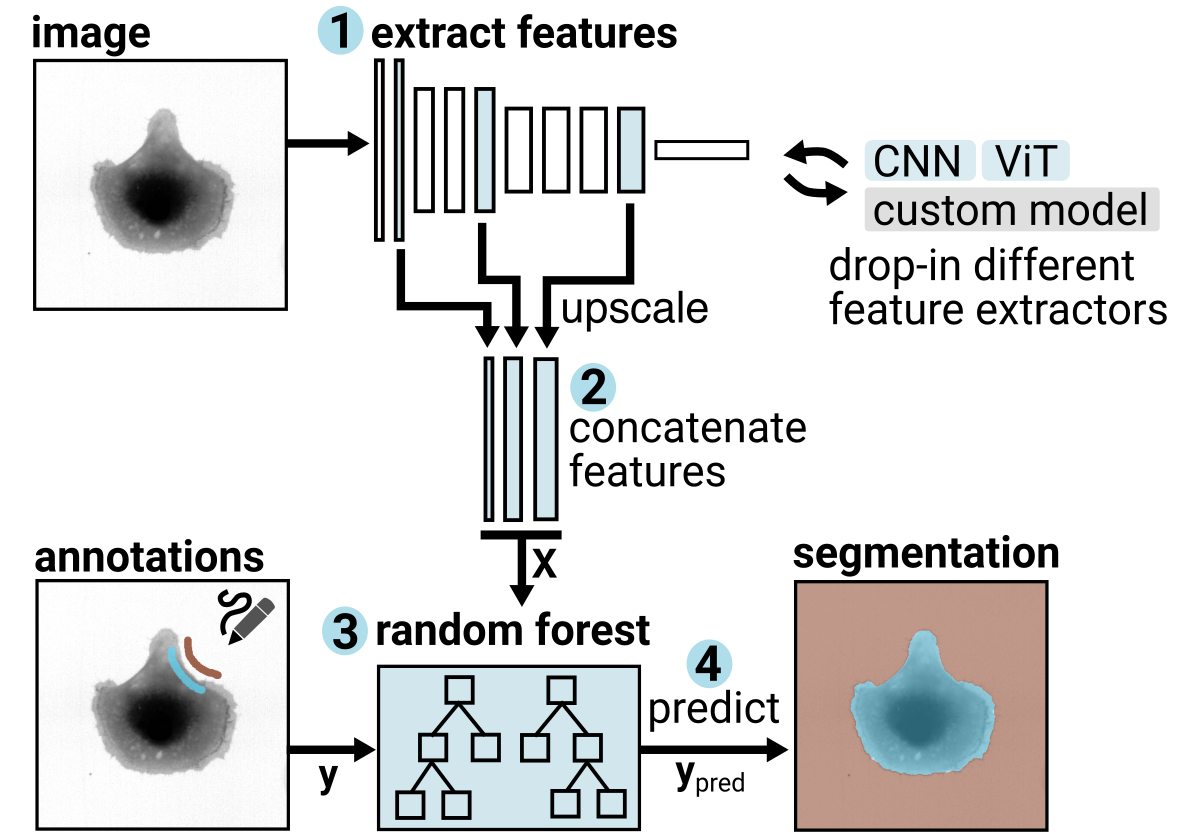
The first step for these machine learning processes is the extraction of some sort of features that are later used to classify each pixel. These features are classically extracted by applying filters on the images at different scales and extracting information such as pixel color, intensity, texture, edge properties etc. Usually the users has to setup the number of features to be extracted and this step will determine the computational power needed.
The innovation in Convpaint is the use of pretrained neural networks, such as convolutional neural networks (CNN) or vision transformers (ViT) to extract those features. Initially, we implemented VGG16, a CNN which was trained on ImageNet, an image dataset containing millions of annotated images. Therefore the “conv” in the name, for convolutional. By now, we have implemented numerous additional popular models and allow to even combine features from multiple extractors. Please refer to the separate page describing the feature extractors currently available in Convpaint. Also, we made the addition of future models particularly straight-forward. Like this, the tool is very flexible and can serve as a framework leveraging the power of state-of-the-art image-analysis models - now, and in the future,
An advantage of using pretrained models instead of hand-picking filters is that the user has no longer to pre-determine the mathematical operations that will be computed to extract the features. In fact, sometimes the user doesn’t have the knowledge to decide which and how many are the most important features, or it would need a long and tedious study to determine that. Instead we let the model decide what are the most important features based on its training on a huge amount of images.
The “paint” in the name refers to the fact that the user has to provide sparse annotation in order for the model to be trained. This part is crucial, as it allows the user to guide the model towards the relevant features without having to specify them explicitly.
The process behind Convpaint is illustrated in this schema:
Besides the default VGG16 CNN, DINOv2 is also available which works well for natural images and movies, e.g. of animals.
One key advantage of using Convpaint instead of the neural network itself is the computational power needed. In fact, running the entire model will be very computationally heavy and in most cases it is not necessary for the classical image segmentation tasks that are the base of each image analysis workflow. Therefore we use the model only to extract features and instead feed a random forest classifier with them which makes this plugin very fast. In this way we have built a very powerful and stable segmentation tool, which can be easily added to any workflow.
Another advantage is that the features extracted from pretrained neural networks extract more information from the data, and often lead to better segmentation results, especially on complex data.
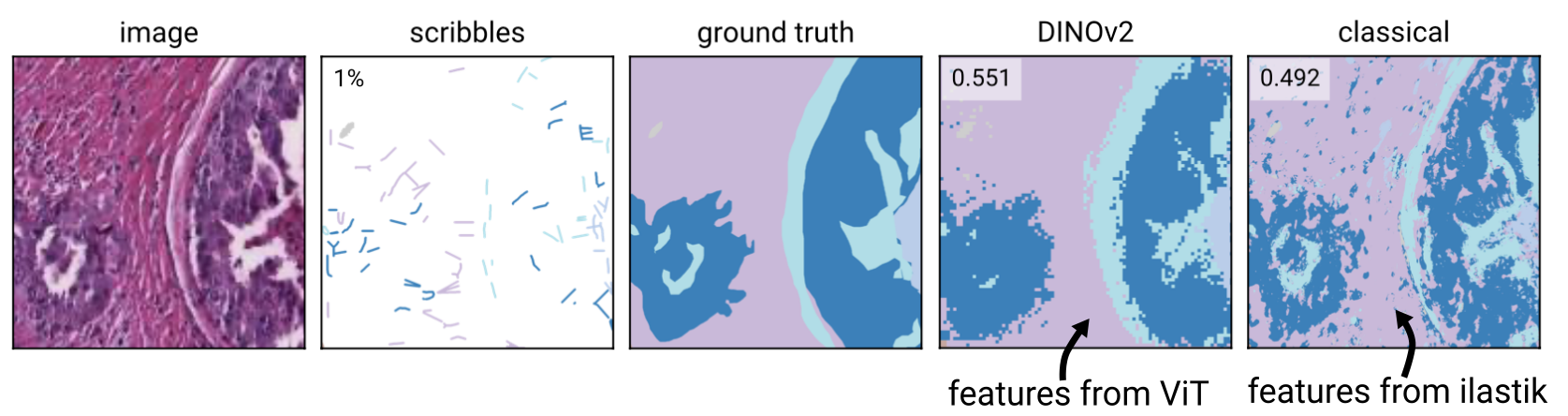
We spent a lot of effort quantifying the performance gains of different feature extractors on different datasets, please check the brief description of all feature extractors for an overview and the preprint of the paper for further information. Here is an example segmentation of a histology dataset, using Convpaint with DINOv2 vs. classical hand-picked filters: