11. Autoencoder
Contents
![]()
11. Autoencoder¶
In the previous chapters, we used neural networks mainly to classify images, and we did that by compressing or encoding the information e.g. by taking in the 28*28=784 pixels of an image and outputing 100 values through a linear layer. Here we will see that instead of using that compression for classification, we can reverse it by adding a decompression or decoding block. Such a network with en encoder and a decoder is called an autoencoder. Such architectures are found in many places in image processing, in particular for denoising, segmentation and generation.
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
import pytorch_lightning as pl
from torchvision import transforms
import numpy as np
import matplotlib.pyplot as plt
# set path containing data folder or use default for Colab (/gdrive/My Drive)
local_folder = "../"
import urllib.request
urllib.request.urlretrieve('https://raw.githubusercontent.com/guiwitz/DLImaging/master/utils/check_colab.py', 'check_colab.py')
from check_colab import set_datapath
colab, datapath = set_datapath(local_folder)
Dataset¶
In this chapter, we use again our quickdraw dataset. Le’t create again our standard dataloader:
transformations = transforms.Compose([
transforms.ToTensor(),
])
from dlcourse import Drawings
num_data = 10000
batch_size = 32
folders = list(datapath.joinpath('data/quickdraw').glob('*npy'))
label_dict = {i:f.name.split('_')[-1][:-4] for i, f in enumerate(folders)}
data = np.concatenate([np.load(f)[0:num_data] for f in folders]) #check everything works with tiny set
labels = np.concatenate([[ind for i in range(num_data)] for ind, f in enumerate(folders)]) #check everything works with tiny set
rng = np.random.default_rng()
indices = rng.choice(len(data), size=len(data), replace=False)
train_loader = DataLoader(Drawings(data, labels, transformations),
sampler=indices[0:int(0.8*len(data))], batch_size=batch_size)
valid_loader = DataLoader(Drawings(data, labels, transformations),
sampler=indices[int(0.8*len(data))::], batch_size=batch_size)
Linear auto-encoder¶
First we adapt some one of the first networks we used and turn our linear classifier into a linear auto-encoder. We use here a very simple auto-encoder: first a fully connected layer that turns the input vector (flattened image) of size width x height into a vector of size encoder_size. Then this vector is re-expanded to the original size again via a fully connected layer.
class Linautoencoder(pl.LightningModule):
def __init__(self, encoder_size):
super(Linautoencoder, self).__init__()
self.lin1 = nn.Linear(28*28, encoder_size)
self.lin2 = nn.Linear(encoder_size, 28*28)
self.loss = nn.MSELoss()
def forward(self, x):
x = x.view(-1,784)
x = F.relu(self.lin1(x))
output = torch.sigmoid(self.lin2(x))
return output
def training_step(self, batch, batch_idx):
x, y = batch
output = self(x)
loss = self.loss(output, x.view(-1,784))
self.log('train/loss', loss, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
output = self(x)
loss = self.loss(output, x.view(-1,784))
self.log('valid/loss', loss, on_epoch=True, prog_bar=True, logger=True)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)
As an extreme example, we will compress the image to a vector of size 4:
mynet = Linautoencoder(encoder_size=4)
im, lab = next(iter(train_loader))
output = mynet(im)
output.shape
torch.Size([32, 784])
trainer = pl.Trainer(max_epochs=10)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
trainer.fit(mynet, train_dataloaders=train_loader, val_dataloaders=valid_loader)
| Name | Type | Params
---------------------------------
0 | lin1 | Linear | 3.1 K
1 | lin2 | Linear | 3.9 K
2 | loss | MSELoss | 0
---------------------------------
7.1 K Trainable params
0 Non-trainable params
7.1 K Total params
0.028 Total estimated model params size (MB)
Validation sanity check: 0%| | 0/2 [00:00<?, ?it/s]
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:659: UserWarning: Your `val_dataloader` has `shuffle=True`, it is strongly recommended that you turn this off for val/test/predict dataloaders.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
Epoch 5: 64%|██████▎ | 597/938 [00:13<00:07, 42.99it/s, loss=0.0844, v_num=4, train/loss_step=0.082, valid/loss=0.085, train/loss_epoch=0.0853]
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py:688: UserWarning: Detected KeyboardInterrupt, attempting graceful shutdown...
rank_zero_warn("Detected KeyboardInterrupt, attempting graceful shutdown...")
Epoch 5: 64%|██████▎ | 597/938 [00:29<00:16, 20.56it/s, loss=0.0844, v_num=4, train/loss_step=0.082, valid/loss=0.085, train/loss_epoch=0.0853]
Now we can check what happens when we compress an image to a vector of 4 values and re-expand it. We just use the validation data for this:
im_valid, lab_valid = next(iter(valid_loader))
pred = mynet(im_valid)
fig, ax = plt.subplots(2,10, figsize=(10,2))
for ind in range(10):
ax[0,ind].imshow(torch.reshape(im_valid[ind],(28,28)))
ax[1,ind].imshow(torch.reshape(pred.detach()[ind],(28,28)))
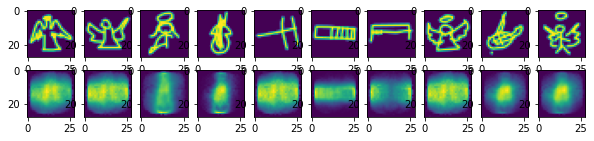
Obviously a lot of information has been lost in the compression. However the outputs are not entirely random and capture some of the image features. Let’s see now if we can improve the result by using convolutions.
Convolutional auto-encoder¶
Convolutions are of course much better at recovering spatial information and make for much better autoencoders. We use here a simple architecture that will server later as basis for a segmentation network. It is composed of a series of:
encoder: convolutions and max-pooling
decoder: transpose convolutions
It would be useful to have access to the encoder and decoder separately. There are multiple ways to do this. Here we simply create two PyTorch modules and then assemble them into a Lightning module:
class Encoder(nn.Module):
def __init__(self, latent_size):
super(Encoder, self).__init__()
self.conv1 = nn.Conv2d(1, 32, stride=2, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, stride = 2, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, stride = 2, kernel_size=3, padding=0)
self.fc = nn.Linear(3*3*128, latent_size)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.fc(x.view(-1, 3*3*128))
return x
class Decoder(nn.Module):
def __init__(self, latent_size):
super(Decoder, self).__init__()
self.fc = nn.Linear(latent_size, 3*3*128)
self.deconv1 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2)
self.deconv2 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1)
self.deconv3 = nn.ConvTranspose2d(32, 1, kernel_size=3, stride=2, padding=1, output_padding=1)
def forward(self, x):
x = self.fc(x)
x = x.view(-1,128,3,3)
x = F.relu(self.deconv1(x))
x = F.relu(self.deconv2(x))
x = torch.sigmoid(self.deconv3(x))
return x
class Convautoencoder(pl.LightningModule):
def __init__(self, latent_size):
super(Convautoencoder, self).__init__()
self.encoder = Encoder(latent_size=latent_size)
self.decoder = Decoder(latent_size=latent_size)
self.loss = nn.MSELoss()
def forward(self, x):
x = self.encoder(x)
output = self.decoder(x)
return output
def training_step(self, batch, batch_idx):
x, y = batch
output = self(x)
loss = self.loss(output.view(-1,784), x.view(-1,784))
self.log('train/loss', loss, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
output = self(x)
loss = self.loss(output.view(-1,784), x.view(-1,784))
self.log('valid/loss', loss, on_epoch=True, prog_bar=True, logger=True)
self.logger.experiment.add_scalar("Loss/Train", loss, self.current_epoch)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)
Now we instantiate our model and train it. We train it again using a latent space (the encoding vector) of size 4. Before anything we verify that all parts of our auto encoder give the correct outputs:
del mynet
mynet = Convautoencoder(latent_size=4)
im, lab = next(iter(train_loader))
out_en = mynet.encoder(im)
out_en.shape
torch.Size([32, 4])
out_de = mynet.decoder(out_en)
out_de.shape
torch.Size([32, 1, 28, 28])
from pytorch_lightning.loggers import TensorBoardLogger
logger = TensorBoardLogger("tb_logs", name="ae")
trainer = pl.Trainer(logger=logger, max_epochs=2)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
trainer.fit(mynet, train_dataloaders=train_loader, val_dataloaders=valid_loader)
| Name | Type | Params
------------------------------------
0 | encoder | Encoder | 97.3 K
1 | decoder | Decoder | 98.3 K
2 | loss | MSELoss | 0
------------------------------------
195 K Trainable params
0 Non-trainable params
195 K Total params
0.782 Total estimated model params size (MB)
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:659: UserWarning: Your `val_dataloader` has `shuffle=True`, it is strongly recommended that you turn this off for val/test/predict dataloaders.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
Epoch 1: 41%|████▏ | 388/938 [00:21<00:30, 17.99it/s, loss=0.0653, v_num=1, train/loss_step=0.0677, valid/loss=0.0679, train/loss_epoch=0.0776]
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py:688: UserWarning: Detected KeyboardInterrupt, attempting graceful shutdown...
rank_zero_warn("Detected KeyboardInterrupt, attempting graceful shutdown...")
Let’s verify the quality of our reconstructions:
%load_ext tensorboard
%tensorboard --logdir tb_logs
im_valid, lab_valid = next(iter(valid_loader))
pred = mynet(im_valid)
fig, ax = plt.subplots(2,10, figsize=(10,2))
for ind in range(10):
ax[0,ind].imshow(torch.reshape(im_valid[ind],(28,28)))
ax[1,ind].imshow(torch.reshape(pred.detach()[ind],(28,28)))
Epoch 1: 43%|████▎ | 402/938 [03:18<04:24, 2.03it/s, loss=0.0734, v_num=0, train/loss_step=0.0717, valid/loss=0.0755, train/loss_epoch=0.0843]
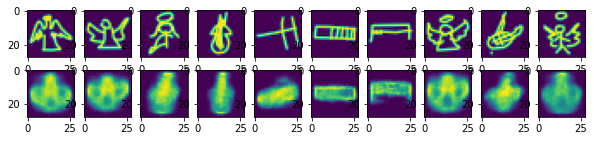
Epoch 1: 41%|████▏ | 388/938 [00:38<00:54, 10.01it/s, loss=0.0653, v_num=1, train/loss_step=0.0677, valid/loss=0.0679, train/loss_epoch=0.0776]
How does the latent space look ?¶
Our network compresses the image information into a N-dimensional vector. In an extreme case we can just use a space of size 2. Then our images can be represented as points in a 2D graph, allowing us to better understand what is happending. Let’s train again our network:
mynet = Convautoencoder(latent_size=2)
trainer = pl.Trainer(logger=logger, max_epochs=2)
trainer.fit(mynet, train_dataloaders=train_loader, val_dataloaders=valid_loader)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
| Name | Type | Params
------------------------------------
0 | encoder | Encoder | 95.0 K
1 | decoder | Decoder | 96.0 K
2 | loss | MSELoss | 0
------------------------------------
190 K Trainable params
0 Non-trainable params
190 K Total params
0.764 Total estimated model params size (MB)
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/callbacks/model_checkpoint.py:631: UserWarning: Checkpoint directory tb_logs/ae/version_1/checkpoints exists and is not empty.
rank_zero_warn(f"Checkpoint directory {dirpath} exists and is not empty.")
Epoch 1: 11%|█▏ | 107/938 [00:05<00:39, 21.01it/s, loss=0.0737, v_num=1, train/loss_step=0.080, valid/loss=0.0757, train/loss_epoch=0.0853]
We now consider all our validation examples. We re-use the random indices that we defined previously and take a 100 images:
test_data = data[indices[int(0.8*len(data)):int(0.8*len(data))+100]]
test_labels = labels[indices[int(0.8*len(data)):int(0.8*len(data))+100]]
outputs = []
labels = []
for val in valid_loader:
outputs.append(mynet.encoder(val[0]))
labels.append(val[1])
outputs = torch.cat(outputs)
labels = torch.cat(labels)
outputs = outputs.detach().numpy()
labels = labels.detach().numpy()
(labels==0).shape
(6000,)
outputs.shape
(6000, 2)
for i in range(3):
plt.scatter(outputs[labels==i,0],outputs[labels==i,1],marker='o', s=1, alpha = 0.5, label=label_dict[i])
plt.legend()
<matplotlib.legend.Legend at 0x142c4d4c0>
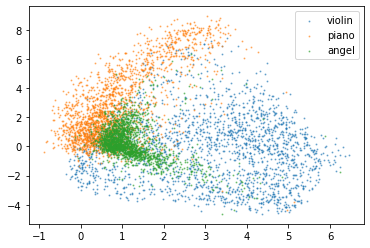
We see that our categories get clustered together. However clustering is not perfect, in particular, the angel category is overlapping with the two others. Violin and piano in contrast are well separated probably because one tends to be roundish, while the other one is square.
We can now even sample from this distribution and generate new images:
gen_image = mynet.decoder(torch.tensor([0, -5], dtype=torch.float32).unsqueeze(0).unsqueeze(0))
plt.imshow(gen_image[0,0].detach())
<matplotlib.image.AxesImage at 0x143a37820>
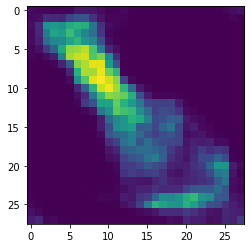
If we choose coordinates clearly belonging to one category we obtain images with the right shapes. In mixed regions or in non-defined regions the results are more random. We will see later that we can improve this generation of image by creating a variational auto-encoder.
Denoising¶
Now that we have a network that can re-create an image after having compressed it, we could use it for denoising. Indeed if an image contains pixels outside of the expected range, those should disappear in the encoding stage so that the reconstructed image is cleaned-up.
Above we trained the network to reproduce the image that has passed through the network. Here we pass a corrupted image through the network but train it to match the uncorrupted version. Here we do this by artifically adding random noise to the image during training. Of course in real situation one would need to acquire images e.g. in good and bad conditions (imagine low vs. high illumination) and use those pairs for training. This is the approach used for example in the CARE software used to restore microscopy images.
We copy here our network and add noise in the training phase:
class Denoiser(pl.LightningModule):
def __init__(self, latent_size):
super(Denoiser, self).__init__()
self.encoder = Encoder(latent_size=latent_size)
self.decoder = Decoder(latent_size=latent_size)
self.loss = nn.MSELoss()
def forward(self, x):
x = self.encoder(x)
output = self.decoder(x)
return output
def training_step(self, batch, batch_idx):
x, y = batch
#!!!!!!!!!!!!!!!!!!!! Add noise here !!!!!!!!!!!!!!!!!!!!!!!!!
x_noise = x + 0.2*torch.randn(x.size())
output = self(x_noise)
loss = self.loss(output.view(-1,784), x.view(-1,784))
self.log('train/loss', loss, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
#!!!!!!!!!!!!!!!!!!!! Add noise here !!!!!!!!!!!!!!!!!!!!!!!!!
x_noise = x + 0.2*torch.randn(x.size())
output = self(x_noise)
loss = self.loss(output.view(-1,784), x.view(-1,784))
self.log('valid/loss', loss, on_epoch=True, prog_bar=True, logger=True)
self.logger.experiment.add_scalar("Loss/Train", loss, self.current_epoch)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)
denois_net = Denoiser(latent_size=100)
from pytorch_lightning.loggers import TensorBoardLogger
logger = TensorBoardLogger("tb_logs", name="ae")
trainer = pl.Trainer(logger=logger, max_epochs=10)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
trainer.fit(denois_net, train_dataloaders=train_loader, val_dataloaders=valid_loader)
| Name | Type | Params
------------------------------------
0 | encoder | Encoder | 207 K
1 | decoder | Decoder | 208 K
2 | loss | MSELoss | 0
------------------------------------
416 K Trainable params
0 Non-trainable params
416 K Total params
1.667 Total estimated model params size (MB)
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:659: UserWarning: Your `val_dataloader` has `shuffle=True`, it is strongly recommended that you turn this off for val/test/predict dataloaders.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, val_dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/data_loading.py:132: UserWarning: The dataloader, train_dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
rank_zero_warn(
Epoch 1: 24%|██▎ | 221/938 [00:10<00:34, 20.55it/s, loss=0.0302, v_num=2, train/loss_step=0.0331, valid/loss=0.0344, train/loss_epoch=0.0575]
/Users/gw18g940/miniconda3/envs/CASImaging/lib/python3.9/site-packages/pytorch_lightning/trainer/trainer.py:688: UserWarning: Detected KeyboardInterrupt, attempting graceful shutdown...
rank_zero_warn("Detected KeyboardInterrupt, attempting graceful shutdown...")
im_valid, lab_valid = next(iter(valid_loader))
im_valid_noise = im_valid + 0.2*torch.randn(im_valid.size())
pred = denois_net(im_valid_noise)
fig, ax = plt.subplots(3,10, figsize=(15,3))
for ind in range(10):
ax[0,ind].imshow(torch.reshape(im_valid[ind],(28,28)))
ax[1,ind].imshow(torch.reshape(im_valid_noise[ind],(28,28)))
ax[2,ind].imshow(torch.reshape(pred.detach()[ind],(28,28)))
Epoch 1: 41%|████▏ | 388/938 [03:36<05:07, 1.79it/s, loss=0.0653, v_num=1, train/loss_step=0.0677, valid/loss=0.0679, train/loss_epoch=0.0776]
Epoch 1: 11%|█▏ | 107/938 [02:17<17:47, 1.28s/it, loss=0.0737, v_num=1, train/loss_step=0.080, valid/loss=0.0757, train/loss_epoch=0.0853]

%load_ext tensorboard
%tensorboard --logdir tb_logs