Predicting categories: logistic regression#
In the past chapters we have seen how we could create an ML model to predict a continuous variable such as the price of an apartment. However very often we want to predict a category, i.e. a discrete value. Such a prediction is generally called classification and can be obtained by multiple methods. Here we will first have a loot at logistic regression, which is conceptually close to the linear regression seen before. We will first try to solve the problem with linear regression to understand why it is not a good solution.
Data exploration#
Here we use a datasets where different types of movements were recorded, resulting in variables indicating acceleration and angular velocity.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
movement = pd.read_csv('../data/movement.csv')
movement.head(5)
| t | x_acc | y_acc | z_acc | x_rot | y_rot | z_rot | move_type | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.001658 | 2.603237 | -0.068707 | 9.457633 | 0.098532 | 0.079406 | -1.539468 | 1 |
| 1 | 0.011610 | 1.871558 | -0.642763 | 10.219399 | 0.128653 | -0.004559 | -1.495045 | 1 |
| 2 | 0.021562 | 1.897454 | -0.996478 | 10.046209 | 0.142974 | -0.081562 | -1.505501 | 1 |
| 3 | 0.031514 | 2.120041 | -0.338596 | 9.839938 | 0.115268 | -0.088669 | -1.557105 | 1 |
| 4 | 0.041466 | 2.452201 | -0.256117 | 9.470506 | 0.050623 | -0.083579 | -1.636483 | 1 |
If we do some data exploration, we can see that the Z acceleration is mostly capable of identifying the two types of movements and we’ll use that as an example.
sns.histplot(data=movement, x='z_acc', hue='move_type', stat='density');
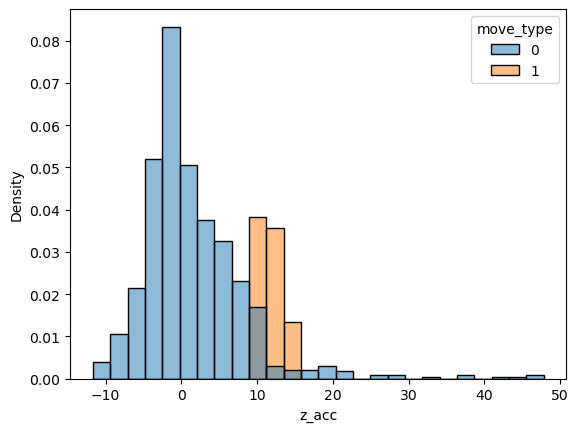
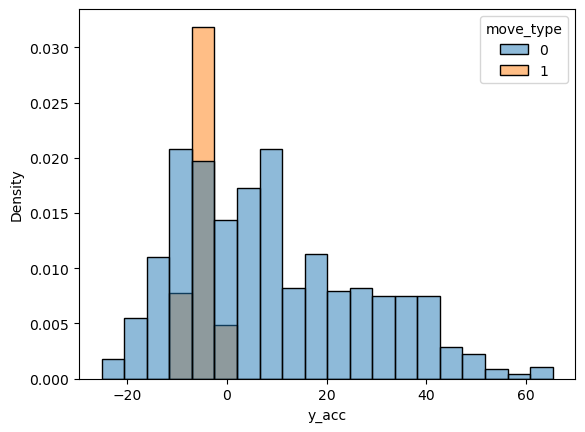
Note that other variables are also different between the two types, but not optimal for binary classification:
sns.histplot(data=movement, x='y_acc', hue='move_type', stat='density');
Linear regression#
Now our task is to predict the move_type feature based on the z_acc feature:
sns.scatterplot(data=movement, x='z_acc', y='move_type');
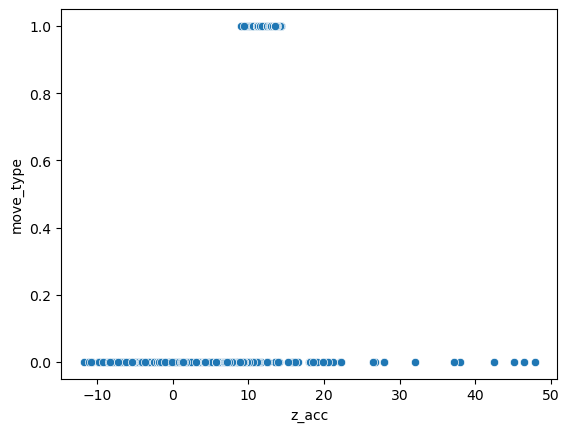
We can first resort to the tool we have seen previously with scikit-learn’s LinearRegression:
from sklearn import linear_model
lin_model = linear_model.LinearRegression()
lin_model.fit(X=movement[['z_acc']], y=movement['move_type'])
pred = lin_model.predict(np.arange(-10,50,1)[:, np.newaxis])
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names
warnings.warn(
sns.scatterplot(data=movement, x='z_acc', y='move_type');
plt.plot(np.arange(-10,50,1), pred, 'r');
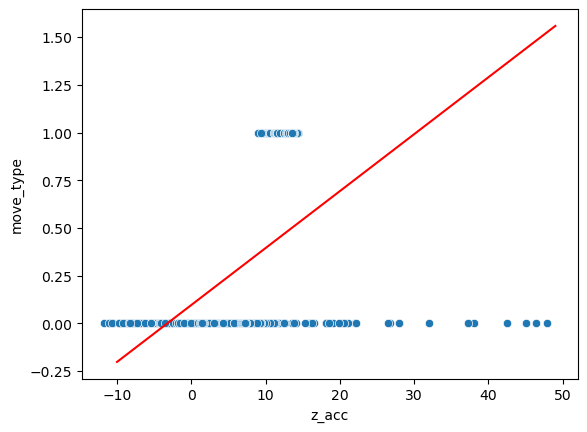
We see that this model is really not appropriate. Of course we could set a limit at 0.5 and say that points below are good and those above bad, but problems remain. For example points with extreme values of acidity have a large weight in the error.
A more appropriate solution would be to pass the linear model directly through a step function. Such a function \(H(x, d)\) takes a value \(x\) and returns 0 if \(x<d\) and 1 if \(x>d\). We can for example set this manually for our data:
def step(x, d):
out = np.zeros(len(x))
out[x>d] = 1
return out
sns.scatterplot(data=movement, x='z_acc', y='move_type');
plt.plot(np.arange(-10,50,1), step(np.arange(-10,50,1), 9), 'r');
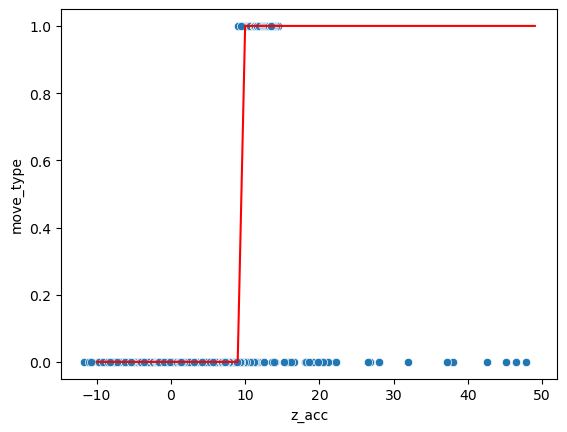
Now we just set the limit at 9 manually. However here too we would like to let the computer find the best threshold value. The problem with the above step function is that it’s not usable for gradient descent. The idea of that method is to slightly vary the parameters of the function to find in which direction the error decreases. However here when we change the parameter d by a small amount, often nothing happens, as no point changes category. So the error landscape if flat and we don’t know in which direction to go!
We have thus to come up with a better function to describe our data. One such function is the sigmoid, which looks like a step function with less sharp edges (the origin of this function can be explained statistically but this is beyond the scope of this course). The sigmoid can be defined with two parameter w which controls the steepness and d again the location:
def sigmoid(x, d, w):
out = 1 / (1 + np.exp(-w*(x-d)))
return out
sns.scatterplot(data=movement, x='z_acc', y='move_type');
plt.plot(np.arange(-10,50,0.1), sigmoid(np.arange(-10,50,0.1), 9, 2), 'r');
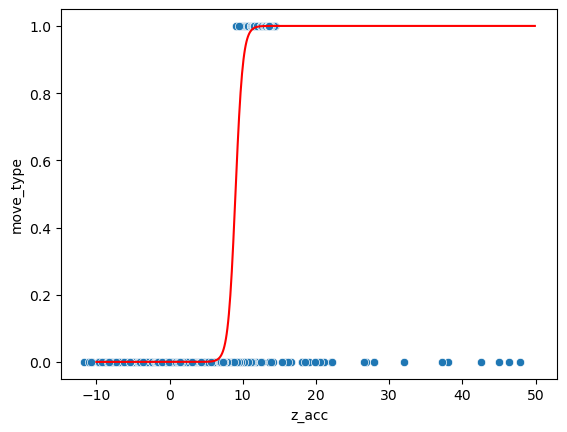
Now we have a continuous result: for example at the acceleration 9 the estimation is 0.5. This number actually offers a probability that a point belongs to the category 1: we are relatively sure that points on the far right belong to category 1 and those on the far left not (and thus belong to category 0) and for the points in the middle we are unsure.
The advantage of this function is that now if we slightly modify w or d, the error will change smoothly and we will be able to estimate slopes for gradient descent!
In fact measuring the error simply as the sum of errors \(\texttt{sigmoid}(x_i, d, w) - y_i\) is still not optimal (the slope is not zero but still very flat) and usually one uses another metric called the cross entropy loss.
Logistic regression in scikit-learn#
Now that we understand why we can’t use simple linear regression, let’s have a look at how to do logistic regression in scikit-learn. Again we create the model and fit it with our data:
log_model = linear_model.LogisticRegression()
log_model.fit(X=movement[['z_acc']], y=movement['move_type'])
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
Now we can use our trained model for predictions. In this case we can both output the probabilities (the actual sigmoid curve) or directly the category:
pred_prob = log_model.predict_proba(np.arange(-10,50,0.1)[:, np.newaxis])
pred = log_model.predict(np.arange(-10,50,0.1)[:, np.newaxis])
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
ax = sns.scatterplot(data=movement, x='z_acc', y='move_type');
ax.plot(np.arange(-10,50,0.1), pred_prob[:,1], 'r', label='probab.')
ax.plot(np.arange(-10,50,0.1), pred, 'g', label='pred. cat.')
ax.legend();
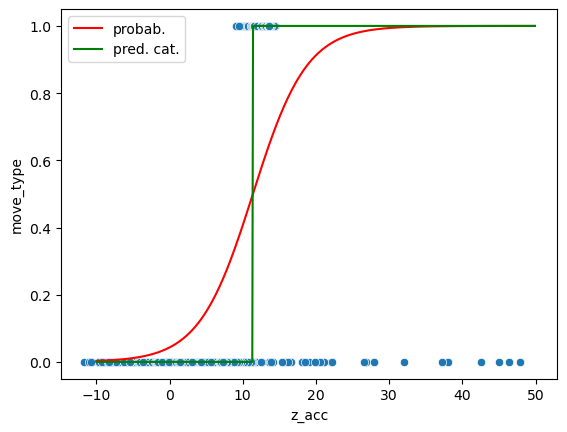
Estimating the error#
For the optimization, we use here by default the cross-entropy loss. This is useful because it provides us a smooth function that is practical for gradient descent. However the actual value that we get is difficult to understand intuitively. To estimate how good our model is, we instead e.g. want to count how many elements were classified properly.
For example we can subtract the actual from the predicted values:
predict_data = log_model.predict(movement[['z_acc']])
movement['move_type'] - predict_data
0 1
1 1
2 1
3 1
4 1
..
996 0
997 0
998 0
999 0
1000 0
Name: move_type, Length: 1001, dtype: int64
Whenever we get 0 here, the prediction was accurate and whenever we get -1 or 1 we miss-classified. Let’s first count bad predictions (we take the absolute values to count -1 as “bad”). We calculate as percentage of all data points:
100* np.sum(np.abs(movement['move_type'] - log_model.predict(movement[['z_acc']]))) / len(movement)
13.986013986013987
And correctly classified:
100* np.sum((movement['move_type'] - log_model.predict(movement[['z_acc']])) == 0) / len(movement)
86.01398601398601
So we have an accuracy of 86%. This seems quite good, but is it as good as it seems?
Checking model quality#
Instead of calculating the success of our model for each category separately. In other words, how good is the model at predicting the two movements separately. If we only select data points that should be either “running” or “rotation” we can just count the correct instances:
np.sum(predict_data[movement['move_type'] == 0] == 0)
763
or as a fraction:
100 * np.sum(predict_data[movement['move_type'] == 0] == 0) / len(movement[movement['move_type'] == 0])
95.375
So here in 95% of cases, when the movement is “running”, we predict it correctly. In contrast for “rotation” movement:
np.sum(predict_data[movement['move_type'] == 1] == 1)
98
np.sum(predict_data[movement['move_type'] == 1] == 0)
103
100 * np.sum(predict_data[movement['move_type'] == 1] == 1) / len(movement[movement['move_type'] == 1])
48.756218905472636
We have a 48% accuracy!
We can compute these errors in one go with scikit-learn using a confusion matrix. Such a matrix will indicate us how many items were in-/correctly classified for each category. We just have to pass actual and predicted values to the function:
from sklearn.metrics import confusion_matrix
confusion_matrix(movement['move_type'], predict_data)
array([[763, 37],
[103, 98]])
We see here again the numbers that we obtained before: 763 and 98 represent the correctly classified items for each category. 103 and 37 represent badly classified ones. Each of these four elements usually has a name. If we consider “classify as running” as positive outcome and “classify as rotation” as negative outcome, then classifying an actual “running” as “running” is a True Positive (TP), classifying an actual “running” as “rotation” is a False Negative etc. You can see all combinations in the figure below:
from IPython.display import display, Image
display(Image('../illustrations/confusion.png'))
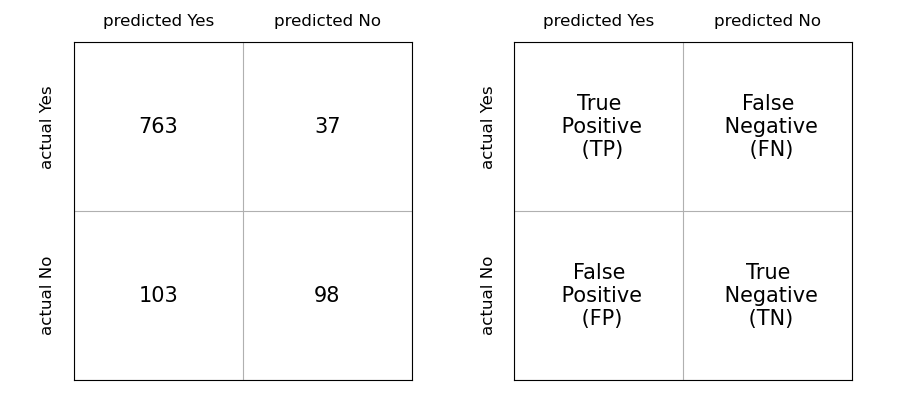
The accuracy that we have measured before consist now in fact of summing up the diagonal and dividing by the total number of data points: \(\texttt{accuracy} = \frac{TP + TN}{TP+TN+FP+FN}\). We will see in a later section that we can come up with better metrics mixing these variables. In the meantime, let’s try to improve our model.
Imbalance#
Why is our model only good with one type of movement? The reason is that we have a strong imbalance between the two categories:
f'Number of "running": {len(movement[movement["move_type"]==0])}'
'Number of "running": 800'
f'Number of "rotation": {len(movement[movement["move_type"]==1])}'
'Number of "rotation": 201'
Let’s imagine what would happen if we had even less examples of “rotation”, e.g. just 2. Then if the model is really dumb and always predicts “running, it would be correct in 99% of cases, without any effort! In such a case, we have to tell the ML model “be careful and be very attentive to these rare cases when learning!”. The way to do this is to give different weights to categories when computing the loss.
A common solution is to give weights inversely proportional to the number of occurrences e.g. 1/217 and 1/63. For the logistic regression we have to pass a list of per-sample weights. We can do this by adding a column to the dataset:
weights = 1/movement['move_type'].value_counts()
movement['weight'] = 1
movement.loc[movement['move_type']==0, 'weight'] = weights[0]
movement.loc[movement['move_type']==1, 'weight'] = weights[1]
/var/folders/mk/632_7fgs4v374qc935pvf9v00000gn/T/ipykernel_93173/10943871.py:2: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise in a future error of pandas. Value '0.00125' has dtype incompatible with int64, please explicitly cast to a compatible dtype first.
movement.loc[movement['move_type']==0, 'weight'] = weights[0]
Let’s try to use this during the fit:
log_model = linear_model.LogisticRegression()
log_model.fit(X=movement[['z_acc']], y=movement['move_type'], sample_weight=movement['weight'])
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression()
pred_prob = log_model.predict_proba(np.arange(-10,50,0.1)[:, np.newaxis])
pred = log_model.predict(np.arange(-10,50,0.1)[:, np.newaxis])
ax = sns.scatterplot(data=movement, x='z_acc', y='move_type');
ax.plot(np.arange(-10,50,0.1), pred_prob[:,1], 'r', label='probab.')
ax.plot(np.arange(-10,50,0.1), pred, 'g', label='pred. cat.')
ax.legend();
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/base.py:465: UserWarning: X does not have valid feature names, but LogisticRegression was fitted with feature names
warnings.warn(
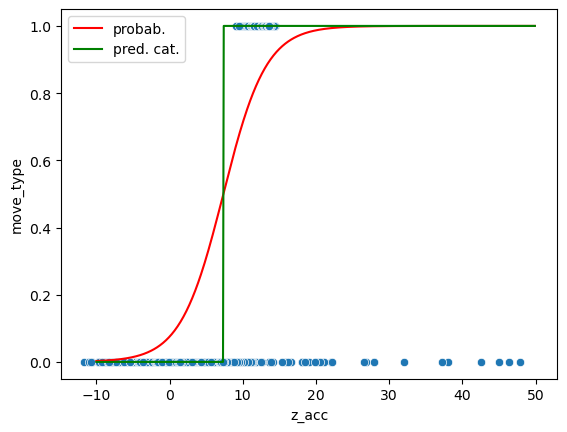
predict_data = log_model.predict(movement[['z_acc']])
confusion_matrix(movement['move_type'], predict_data)
array([[690, 110],
[ 0, 201]])
print('True negative rate')
100 * np.sum(predict_data[movement['move_type'] == 1] == 1) / len(movement[movement['move_type'] == 1])
True negative rate
100.0
print('True positive rate')
100 * np.sum(predict_data[movement['move_type'] == 0] == 0) / len(movement[movement['move_type'] == 0])
True positive rate
86.25
We see that we managed to massively improve the number of negatives that we predict correctly, at a minor cost for the prediction of true positives!
Such weights are used very often in almost any method, including e.g. Deep Learning. For example you could imagine trying to detect tiny objects in a large image. In such a case you would need to give a large weight to pixels corresponding to the tiny objects.
Other metrics#
We have seen before that we could define the True/False Positive/Negative quantities. We also saw that we could use these variables to define quality metrics such as the \(\texttt{accuracy} = \frac{TP + TN}{TP+TN+FP+FN}\).
We can however define other variables that are commonly used in machine learning. Two of the most important ones are precision and recall. The precision, as the name says, indicates how precise our model is: it tells us the fraction of positives which are actually true positives and not false positives and is defined as \(\texttt{precision} = \frac{TP}{TP+FP}\). The recall tells us if we are missing a lot of positives because we miss some as false negatives and is defined as \(\texttt{recall} = \frac{TP}{TP+FN}\). Ideally we would like to have high precision, i.e. as few FPs as possible. But this doesn’t say anything about the number of TP that we have: we could have very few TP and FP and still have high precision. So we need to also look at recall and have a recall as high as possible too, i.e. as few FN as possible.
Let’s consider a simple example where we classify pictures of cats and dogs and end up with the following results:
display(Image('../illustrations/confusion_cats.png'))
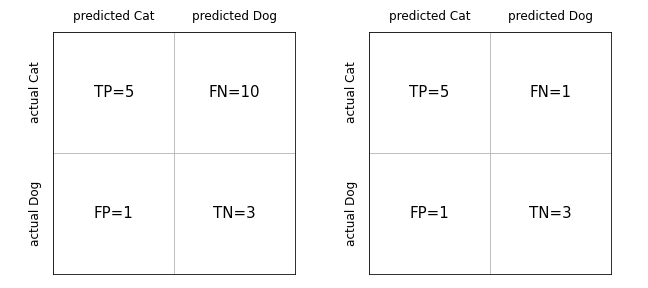
We have here the same precision on the left and the right \(\texttt{precision} = \frac{5}{5+1} = 0.83\). So we have few actual dog pictures that we classify as cats. But what about the recall? On the left, we have \(\texttt{recall} = \frac{5}{5+10} = 0.33\). This is bad, we are missing a lot of cat pictures. So those we predict as cats are usually cats, but we miss many of them! On the right, we have a much better result with \(\texttt{recall} = \frac{5}{5+1} = 0.83\).
One can define many other such variables. One important one, summarizes precision and recall and is called F-score: \(F = 2 * \frac{\texttt{precision}\; x \;\texttt{recall}}{\texttt{precision}\; + \;\texttt{recall}}\). In our examples above we get \(F=0.47\) on the left and \(F=0.83\) on the right.
Depending on the problem, one might prefer maximizing one or the other metric. For example if we think of a covid-test, we would obviously like to try maximizing both precision and recall, but if there are technical trade-offs, we would prefer to detect infectious people all the time (good recall) at the cost of precision (some people will get a positive test even though they are not infectious).
Metrics in scikit-learn#
Of course we get access to all these metrics via scikit-learn. There are specific functions like precision_socre but we can also get a summary of all values with either precision_recall_fscore_support or classification_report.
from sklearn.metrics import f1_score, precision_score, recall_score, precision_recall_fscore_support, classification_report
First we redo our classification, once with and once without weights:
log_model_noweight = linear_model.LogisticRegression()
log_model_noweight.fit(X=movement[['z_acc']], y=movement['move_type'])
log_model_weight = linear_model.LogisticRegression()
log_model_weight.fit(X=movement[['z_acc']], y=movement['move_type'], sample_weight=movement['move_type']);
predict_data_noweigth = log_model_noweight.predict(movement[['z_acc']])
predict_data_weigth = log_model_weight.predict(movement[['z_acc']])
Now we compute can look at the reports:
print(classification_report(movement['move_type'], predict_data_weigth))
precision recall f1-score support
0 0.00 0.00 0.00 800
1 0.20 1.00 0.33 201
accuracy 0.20 1001
macro avg 0.10 0.50 0.17 1001
weighted avg 0.04 0.20 0.07 1001
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1471: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1471: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
/Users/gw18g940/mambaforge/envs/DAVPy2023/lib/python3.10/site-packages/sklearn/metrics/_classification.py:1471: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
print(classification_report(movement['move_type'], predict_data_noweigth))
precision recall f1-score support
0 0.88 0.95 0.92 800
1 0.73 0.49 0.58 201
accuracy 0.86 1001
macro avg 0.80 0.72 0.75 1001
weighted avg 0.85 0.86 0.85 1001
We see that we get scores for both categories. Again, depending on wehter the outcome is binary (sick, not sick) or not (cats, dogs) we might have interest in having scores for all categories. In the latter case, we can then also look at the average scores like the f1-score. We see in the example above that the macro average F1-score improves when we use weights.
Exercise#
Import the housing.csv dataset. The
good_badfeature is an “artifical” binary feature indicating if the house is nice or not.Use logistic regression to predict the
good_badfeature withsqft_livingFind the accuracy of your model.
Print a report of the scores of the classification